Reefspawn workflow

1) Simulate reef area
simulate a reef plot 16m long by 8m wide (note: the default crs (EPSG:3857) is projected but not lon/lat degrees). Colony sizes are drawn from posterior of brms (see ?posterior_coral_predict and model parameterisation for details) or can be input from survey data.
library(reefspawn)
sf_plot <- setplot(16,8) # default EPSG:3857
# set up brms predictions from posterior
coralsizepredictions <- posterior_coral_predict(brm_sizedistribution, ndraws=1000, newdata=coralsize)2) Simulate coral communities
Simulate coral communities at 40% cover within the 128 [m^2] plot. Communities are structured from 11 species across five different growthforms: tabular corals (Acropora cytherea, A. hyacinthus), corymbose corals (A. millepora, A. nasuta, A. spathulata), digitate corals (A. humilis, A. digitifera), branching corals (A. intermedia, A. robusta), and massive corals (Goniastrea pectinata, G. retiformis).
The function builds coral communities based on observed colony sizes from Lizard Island from 2009 to 2015 (~ 30 colonies from each of 11 species, Madin et al 2023) and simulates a 40% cover reef. Community structure is based on a pre-determined ratio of growth forms (tabular = 0.7, digitate = 0.075, corymbose = 0.125, branching = 0.08, massive = 0.02) that is assigned across the 11 species. The exact coral cover is stochastic and sampled from the beta distribution (alpha=12, beta=4) to vary ~40% cover when running multiple simulations. plot = TRUE returns a full summary of paramterisation.
for details see ?reefspawn::simulate_communities()
communities <- simulate_community(setplot = sf_plot,
coralcover=40,
size = coralsize,
ratiovar = 0.2,
alpha = 24,
beta = 8,
seed = 321,
plot = TRUE,
quiet = TRUE)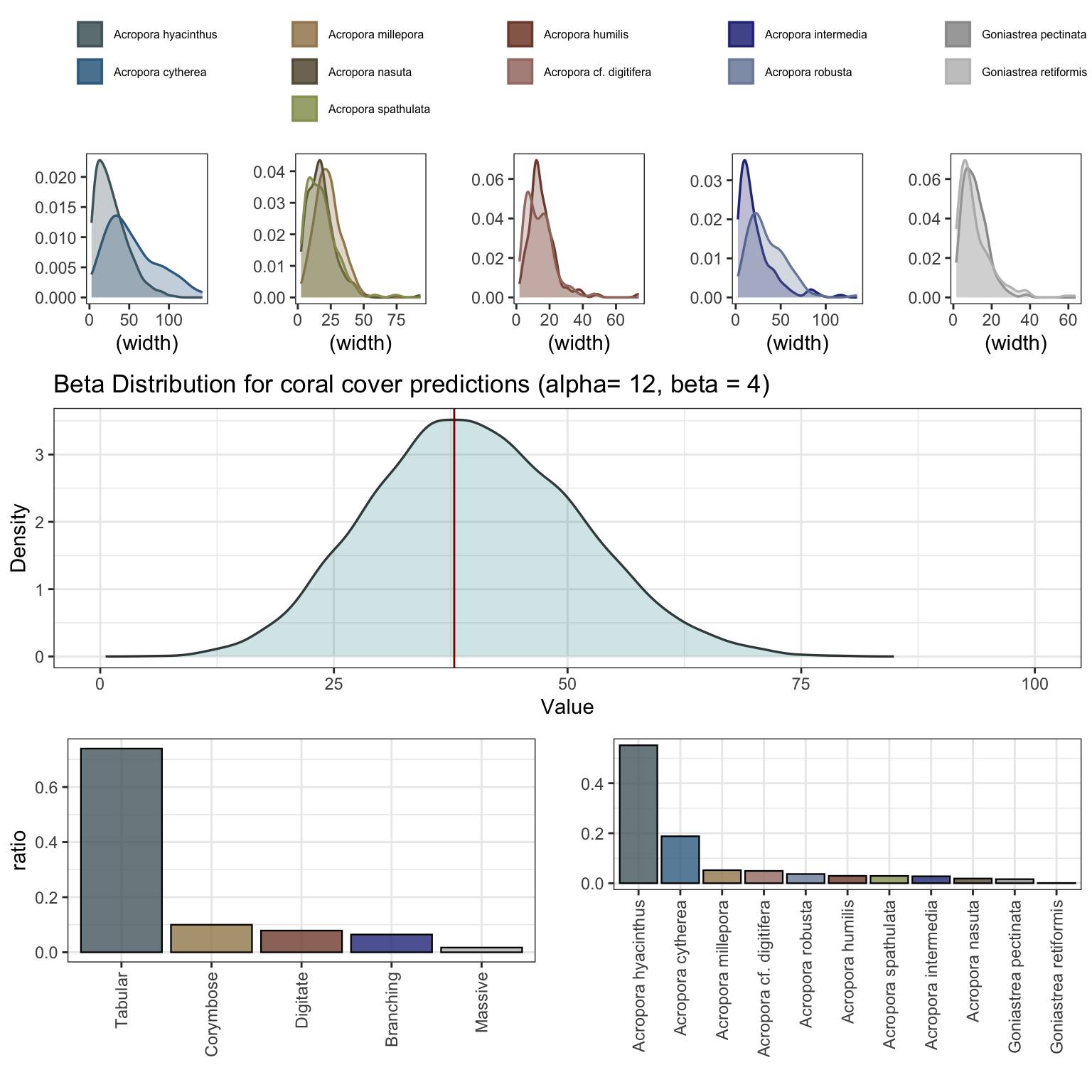
3) Simulate coral populations
From the simulated community output (% cover of each of the 11 species), simulate_populations() takes the output of bayesian model predictions for the size distributions (based on Lizard Island data) and simulates populations to fill the percent cover for each species. The function outputs either df - a dataframe of individals and size distribution, or an sf simple features with corresponding sizes and coordinates within the initial plot. The coral size data is included in the package in coralsize and can be replaced or updated with additional data for flexible parameterisation.
The spatial mapping in sf uses a species hierarchy approach to determining the most likely spatial competitor for initial population space, and sets a maximum overlap between colonies at random using a normal distribution (max 90% overlap) for each colony to simulate a spatially realistic coral population. The spatial coordinates of each colony are determined using a circle packing algorithm within the initial plot using an iterative pair-wise repulsion approach to find non-overlapping colonies in space. The approach is rapid (<2 mins) for small plots (<100m^2) and population densities <5000 colonies, but rapidly saturates and becomes time consuming above this number - for large plots subsetting into smaller plots (ideally using a a parallel approach) is computationally less taxing. The output is spatially referenced
for details see ?reefspawn::simulate_populations()
populations <- simulate_populations(setplot = sf_plot,
size = coralsize,
community = communities,
return = "sf",
ndraws = 2000,
seed = 321,
interactive = TRUE,
quiet = TRUE)
head(populations)Simple feature collection with 6 features and 12 fields
Active geometry column: geometry
Geometry type: POLYGON
Dimension: XY
Bounding box: xmin: 2.917146 ymin: 3.207861 xmax: 16.64492 ymax: 8.070604
Projected CRS: WGS 84 / Pseudo-Mercator
# A tibble: 6 × 14
id geometry species width area cumulative_area aerial
<int> <POLYGON [m]> <fct> <dbl> <dbl> <dbl> <dbl>
1 1 ((3.295555 5.729159, 3.2895… Acropo… 37.2 0.109 1086. 2.68e5
2 2 ((5.249227 5.032149, 5.2467… Acropo… 14.9 0.0174 1259. 2.68e5
3 3 ((12.74873 5.188348, 12.732… Acropo… 95.8 0.720 8462. 2.68e5
4 4 ((5.756184 7.621999, 5.7420… Acropo… 84.2 0.556 14026. 2.68e5
5 5 ((16.64492 3.893052, 16.623… Acropo… 132. 1.36 27652. 2.68e5
6 6 ((9.369746 7.00418, 9.36136… Acropo… 49.1 0.189 29546. 2.68e5
# ℹ 7 more variables: coords <POINT [m]>, zindex_id <int>, species.id <chr>,
# x <dbl>, y <dbl>, overlaparea <dbl>, status <chr>4) Map coral populations
map_populations visualises the output of simulate_populations in XY space. sum(populations$area) will return the combined area of corals, (sum(populations$area) / as.numeric(sum(st_area(sf_plot)))) *100 the percent cover.
for static maps:
map_populations(setplot = sf_plot,
populations = populations,
interactive = FALSE,
webgl = TRUE)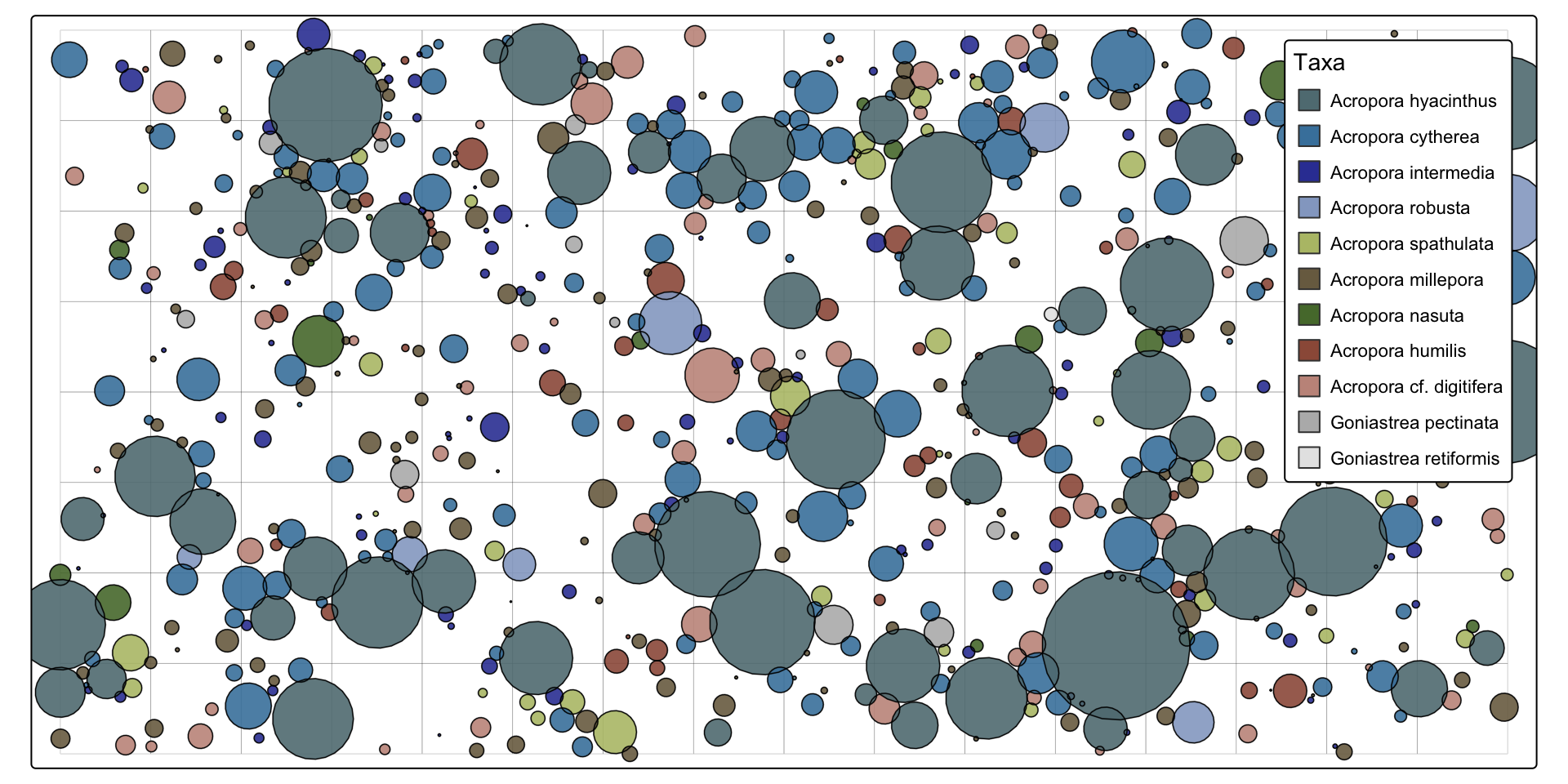
for interactive maps:
map_populations(setplot = sf_plot,
populations = populations,
interactive = TRUE)for details see ?reefspawn::map_populations()
5) Simulate spawning
simulate_spawning takes the colonies from populations and parameterises a per colony output of oocytes based on Bayesian models fit to data from Lizard Island (Álvarez-Noriega et al 2016). The function uses posterior_predict from the brms models to sample draws from the posterior predictive distribution of the observed data (i.e. adds model uncertainty + residual (observation-level) noise). For each colony, the function predicts the total number of polyps, proportion of the polyps that are reproductive (i.e. not within the sterile zone at growth margins), the number of oocytes per polyp, and the probability of colonies being reproductive (binomial).
$where:$'$- \( P \) = polyp density (polyps per cm²)$’ $- \( A \) = colony area in m²$'$- \( S \) = sterile proportion$‘$- \( O \) = oocytes per reproductive polyp$'$- \( R \) = reproductive probability$’
See the brm page for exact paramterisation and code for models. The model fits are included in the package (brm_fecundity, brm_probability, brm_polyp_density, brm_sizedistribution) and can be flexibly paramaterised with updated data.
for details see ?reefspawn::simulate_spawning()
reproductiveoutput <- simulate_spawning(populations = populations,
setplot = sf_plot,
seed = 1001,
quiet = FALSE,
plot = TRUE)[1] "3.388 sec elapsed - simulate_populations()"
[1] "31,956,783 - total reproductive output"
[1] "249,662 - reproductive output per m2"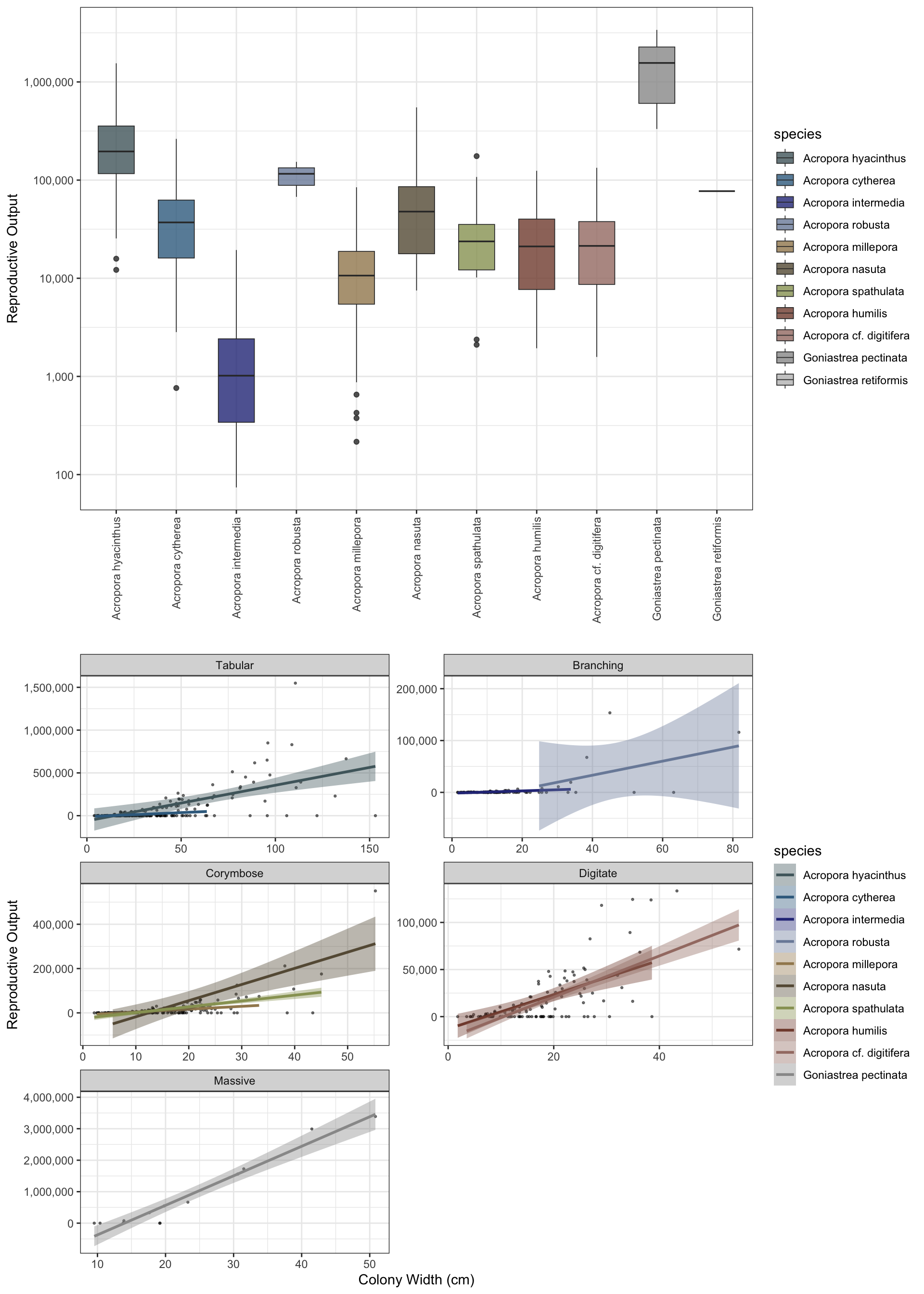
To run large datasets or parallel processing / mulitcore use return="df"instead of return="sf" and bypass the sf functionality.
Example below for a hectare plot returns reproductive outputs from 96,490 colonies in 38 seconds
sf_plot_large <- setplot(100,100)
hectare_output <- simulate_community(setplot = sf_plot_large,
coralcover=40,
size = coralsize |> dplyr::filter(year==2011),
seed = 321,
plot = FALSE,
quiet = TRUE) %>%
simulate_populations(community = .,
seed = 321,
return="df") %>%
simulate_spawning(populations = .,
seed = 321)
hectare_summary <- hectare_output |>
dplyr::group_by(species) |>
dplyr::summarise(output = sum(output)) |>
dplyr::mutate(output = format(output, big.mark = ",", scientific = FALSE)) %>%
dplyr::bind_rows(
dplyr::summarise(., species = "Total", output = format(sum(as.numeric(gsub(",", "", output))), big.mark = ","))
)
reactable::reactable(
head(hectare_summary, 20),
defaultPageSize = 20,
pagination = FALSE,
searchable = FALSE,
highlight = TRUE,
bordered = TRUE,
striped = TRUE
)